Explanation of why Neural Networks are non convex
Data Science Asked on April 27, 2021
Why having a symmetry of values for the hidden state imply that the neural network is non convex? I could not find an intuitive answer for this yet.
Also, if we consider a Fully Connected network wtih ReLU non linearity(which is convex) then it is a composition of convex functions and ReLU is also non decreasing. Still the overall optimization problem becomes non convex.
I am a bit confused and any help would be highly appreciated.
Can someone please help me out here
One Answer
To answer the question so it is not presented as unanswered:
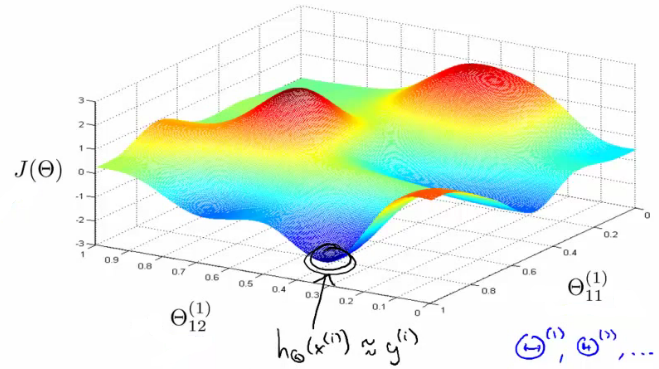
How does this relate to our neural network? A cost function $J(W,b)$ has also a number of local maxima and minima, as you can see in this picture, for example.
The fact that $J$ has multiple minima can also be interpreted in a nice way. In each layer, you use multiple nodes which are assigned different parameters to make the cost function small. Except for the values of the parameters, these nodes are the same. So you could exchange the parameters of the first node in one layer with those of the second node in the same layer, and accounting for this change in the subsequent layers. You'd end up with a different set of parameters, but the value of the cost function can't be distinguished by (basically you just moved a node, to another place, but kept all the inputs/outputs the same).
I don’t remember where I heard this arguement but it was a pretty interesting one and I couldn’t remember the entire reasoning and so as I began to think about it, I figured some of it out and I believe it is pretty reasonable. We have all argued that neural networks are difficult to optimize because they are non-convex(or non-concave) for that matter. What we don’t talk about so much is why is it that they are non-convex. It probably has simpler answers where you will argue something about the non-linearities involved. This post has to do with a much more interesting answer.
To understand the reasoning, we have to argue that if the function has atleast two local minimas such that their mid-point is not a local minima, the function is non-convex. In formal terms, $$text{If > }exists x,y in Dom(f) hspace{5pt }s.t.hspace{5pt} g(x) = g(y) = 0 > $$ and $$forall zin [x,y] text{ s.t. } g(z) neq 0 $$ where $g(x)$ is a subgradient at $x$ the function is non-convex.
This is pretty simple to follow from the Mid-point value theorem and the definition of convexity.
Consider a neural network $F(cdot)$ with a few layers and name three layers $L_1, L_2$ and $ L_3$ Consider nodes $a$ and $b$ in $L_1$ and $c$ and $d$ in $L_2$.Let the parameters connecting node $i$ to $j$ be called $w_{ij}$.
Thee arguement to the function can be thought of as $A=[cdots w_{ac}, > w_{ad}, cdots , w_{bc}, w_{bd}cdots]$ and the function evaluation as $f(A)$. Consider $B=[cdots w_{ad}, w_{ac},cdots, w_{bd}, w_{bc}, > cdots]$. I can claim that there exists a $B$ i.e. where $ w_{ad}, > w_{ac}$ and $ w_{bd}, w_{bc} $ are swapped respectively, there exists an ordering of the other weights(permute the other edges) such that the function evaluation remains same. It is pretty easy to see how it can be true.
Look at the following picture where the reg edges come into one node and the green into another.
For reference consider
- The first red edge coming out of the top left node as $w_{ac}$
- The gree edge out of the same node as $w_{ad}$.
- The red edge out of the second node in the same layer as $w_{bc}$
- The green edge out of the second node as $ w_{bd} $.
Connect all edges coming in to $L_2$ from $L_1$ into node $d$ to node $c$ and vice versa and then shift the origin of all outgoing edges from node $c$ to $L_3$ to node $d$ and vice versa. What you have acheived is the network that you would have achieved by holding the two nodes by your hand and manually exchanging their positions while keeping the connecting edges intact. And Voila! now you have $A, B in > dom(F)$ where $F(A) = F(B) $.
Now look at them after the edges are shifted.
[..]What this effectively means is that if the neural network was indeed convex, there would be a value which could be given to all nodes in a layer and yet the network would have represented a local optima. This is higly absurd and is very apparent if you consider a classification network where the final outputs should not have the same value in all nodes given some value in the input layer(which is also a part of the function arguement).
To generalize this to any neural network, you will have to look at the activation functions and their properties. The claim you will be trying to verify is that the average of two permutations of an optimal point need not be optimal. I guess this was an interesting read. A very interesting thing this says is that
A neural network cannot have a unique optima if it has atleast two distinct node values in the same layer. Amazing , isn’t it ?


{kind=link}
References:
Answered by Nikos M. on April 27, 2021
Add your own answers!
Ask a Question
Get help from others!
Recent Answers
- haakon.io on Why fry rice before boiling?
- Joshua Engel on Why fry rice before boiling?
- Jon Church on Why fry rice before boiling?
- Lex on Does Google Analytics track 404 page responses as valid page views?
- Peter Machado on Why fry rice before boiling?
Recent Questions
- How can I transform graph image into a tikzpicture LaTeX code?
- How Do I Get The Ifruit App Off Of Gta 5 / Grand Theft Auto 5
- Iv’e designed a space elevator using a series of lasers. do you know anybody i could submit the designs too that could manufacture the concept and put it to use
- Need help finding a book. Female OP protagonist, magic
- Why is the WWF pending games (“Your turn”) area replaced w/ a column of “Bonus & Reward”gift boxes?