Different results for LogisticRegression on python 2.7 and 3
Data Science Asked by Mutatos on December 14, 2020
I have different results for the same kernel on python 2.7 (local machine) and python3 (the system running on kaggle) for LogisticRegression. How it is possible?
Here my results from my local machine:
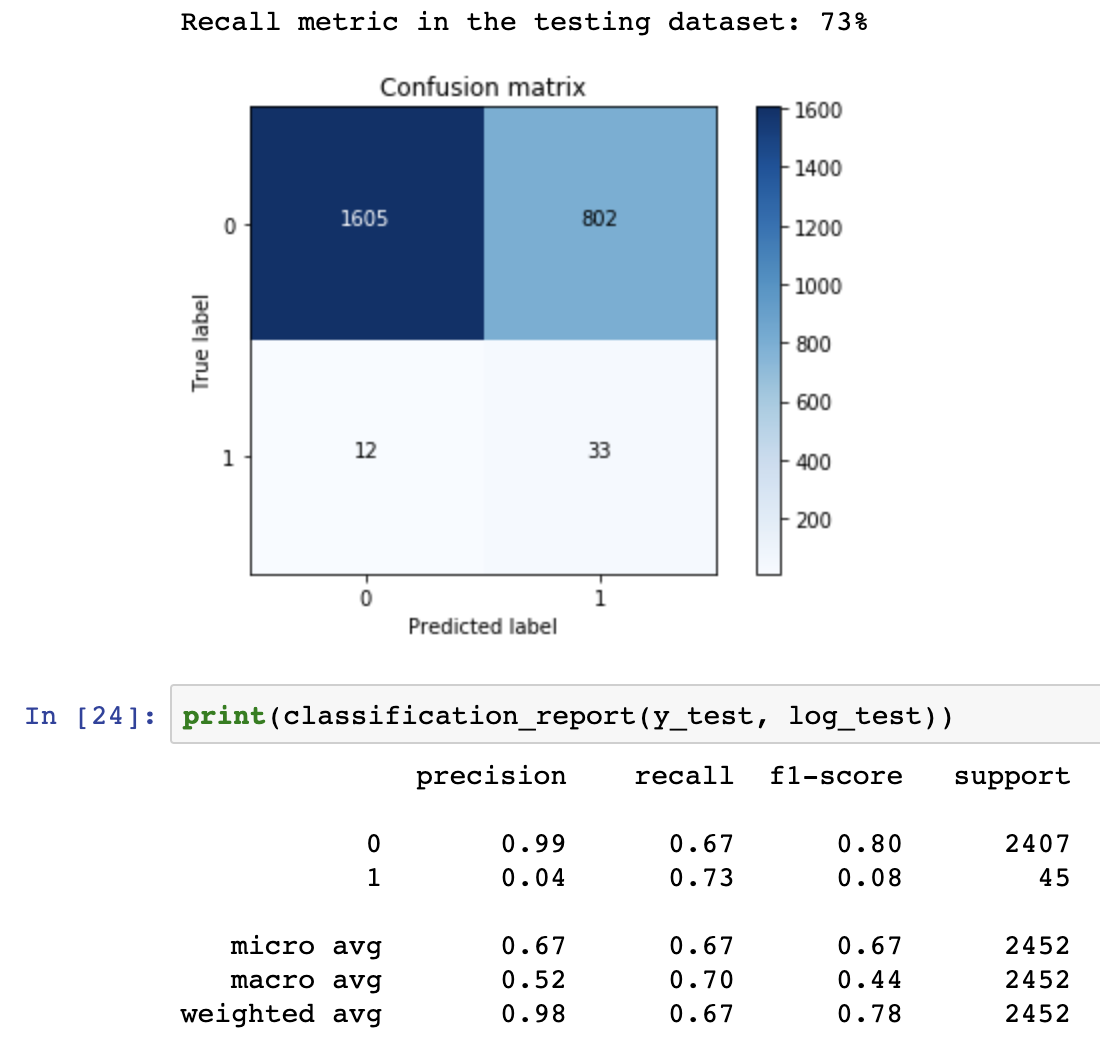
Here from the kaggle notebook:
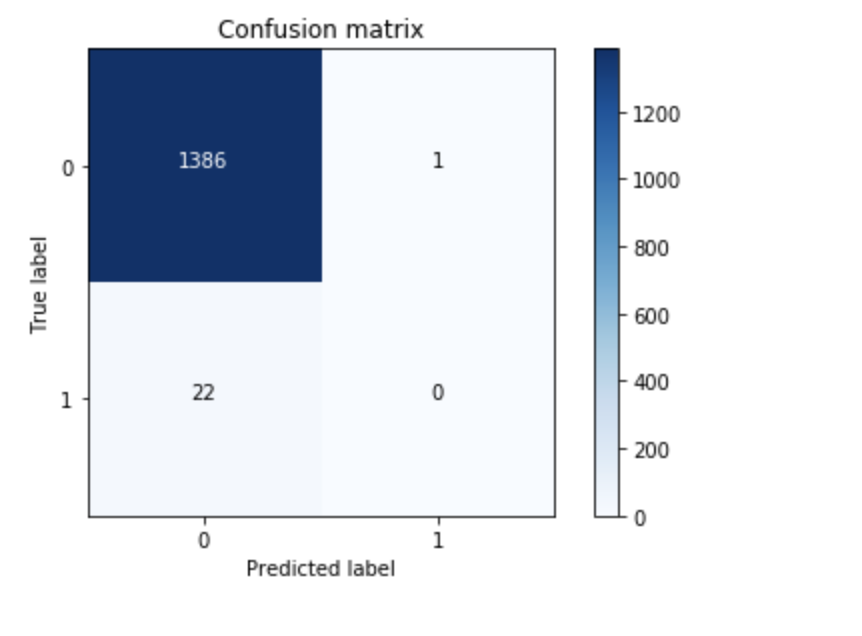
The amount of data is different, because I split a bit more for the train data, but the predictions are totally different. Can this be because of the versions of python?
2 Answers
Assuming that you are using sklearn, if you go to the source in the github you will see that they do not differ.
But you have variability elsewhere. For example train_test_split of sklearn also takes random seed, so it could be that your data is fundamentally different between these approaches (you could do cross valdiation for example to include all the data in train and test)
Answered by Noah Weber on December 14, 2020
The main problem was the ordinal data transformation. Python 2.7 somehow has detected the ordinal data and works with it. In python3 I have to convert the ordinal data with:
from sklearn.preprocessing import OrdinalEncoder
encoder = OrdinalEncoder()
train_df.F1 = encoder.fit_transform(train_df.F1.values.reshape(-1, 1))
Now it works with python3 also!
Answered by Mutatos on December 14, 2020
Add your own answers!
Ask a Question
Get help from others!
Recent Answers
- Jon Church on Why fry rice before boiling?
- Peter Machado on Why fry rice before boiling?
- haakon.io on Why fry rice before boiling?
- Lex on Does Google Analytics track 404 page responses as valid page views?
- Joshua Engel on Why fry rice before boiling?
Recent Questions
- How can I transform graph image into a tikzpicture LaTeX code?
- How Do I Get The Ifruit App Off Of Gta 5 / Grand Theft Auto 5
- Iv’e designed a space elevator using a series of lasers. do you know anybody i could submit the designs too that could manufacture the concept and put it to use
- Need help finding a book. Female OP protagonist, magic
- Why is the WWF pending games (“Your turn”) area replaced w/ a column of “Bonus & Reward”gift boxes?